Introduction¶
What is dhSegment?¶
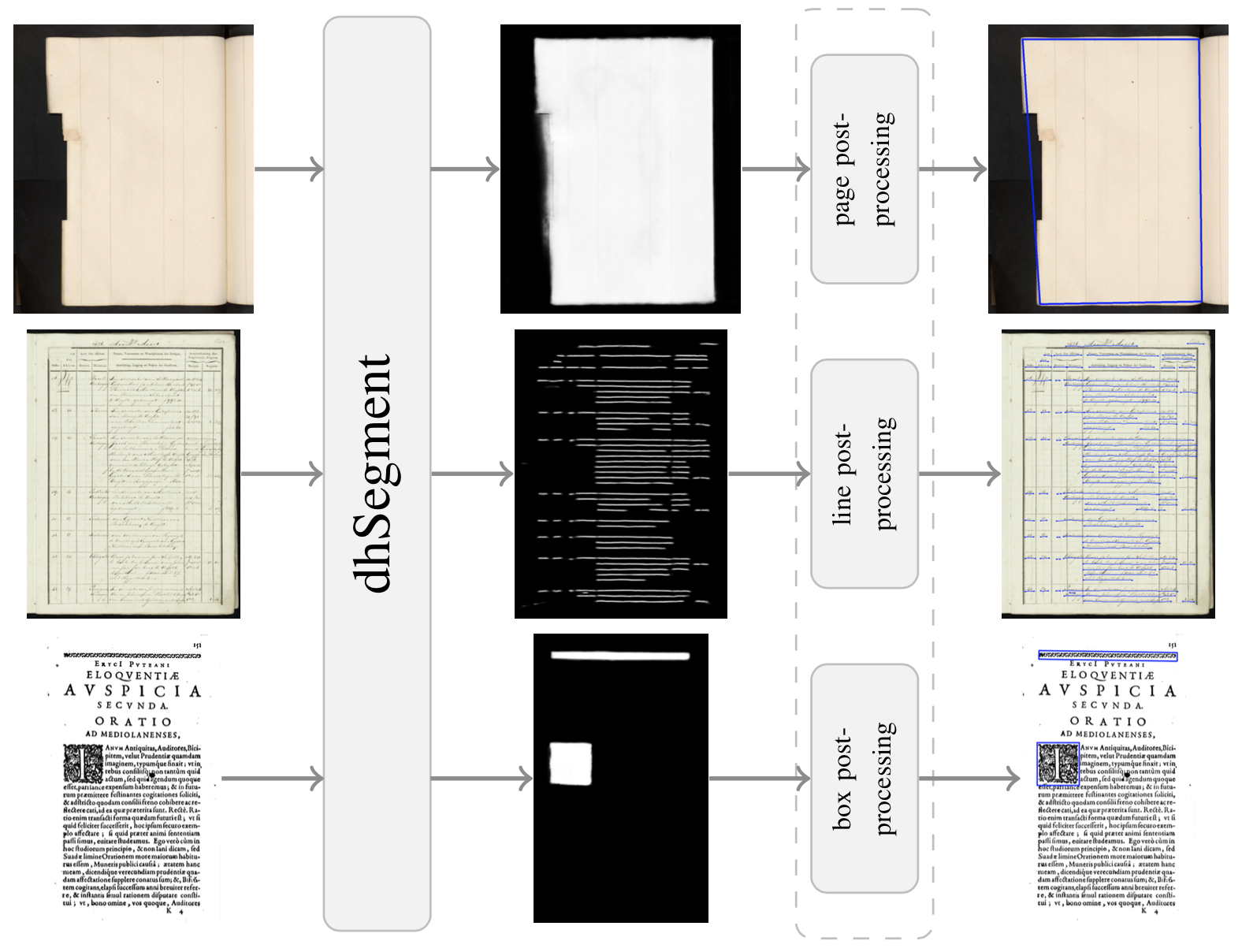
dhSegment is a generic approach for Historical Document Processing. It relies on a Convolutional Neural Network to do the heavy lifting of predicting pixelwise characteristics. Then simple image processing operations are provided to extract the components of interest (boxes, polygons, lines, masks, …)
A few key facts:
You only need to provide a list of images with annotated masks, which can easily be created with an image editing software (Gimp, Photoshop). You only need to draw the elements you care about!
Allows to classify each pixel across multiple classes, with the possibility of assigning multiple labels per pixel.
On-the-fly data augmentation, and efficient batching of batches.
Leverages a state-of-the-art pre-trained network (Resnet50) to lower the need for training data and improve generalization.
Monitor training on Tensorboard very easily.
A list of simple image processing operations are already implemented such that the post-processing steps only take a couple of lines.
What sort of training data do I need?¶
Each training sample consists in an image of a document and its corresponding parts to be predicted.


Additionally, a text file encoding the RGB values of the classes needs to be provided. In this case if we want the classes ‘background’, ‘document’ and ‘photograph’ to be respectively classes 0, 1, and 2 we need to encode their color line-by-line:
0 255 0
255 0 0
0 0 255
Use cases¶






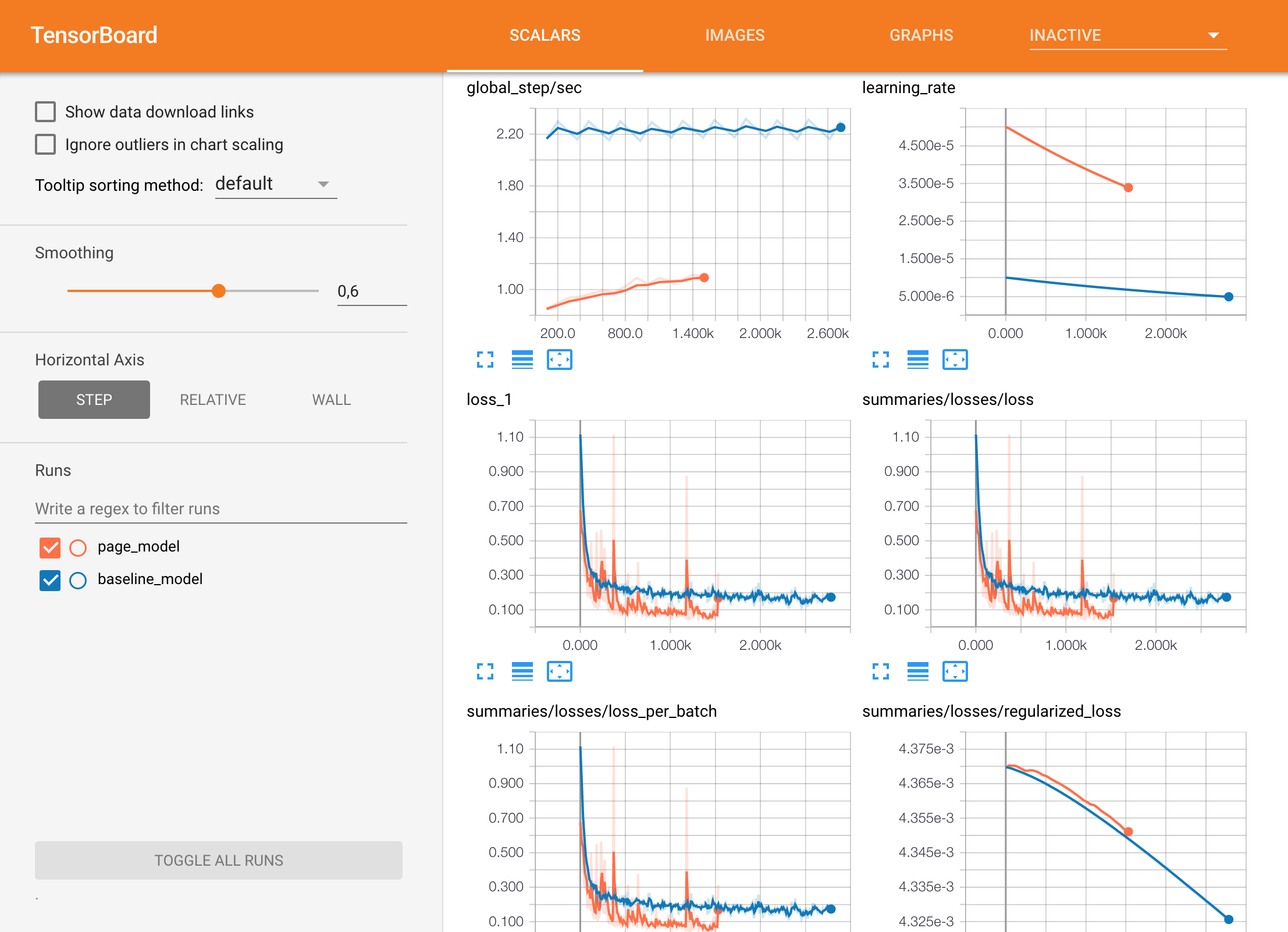
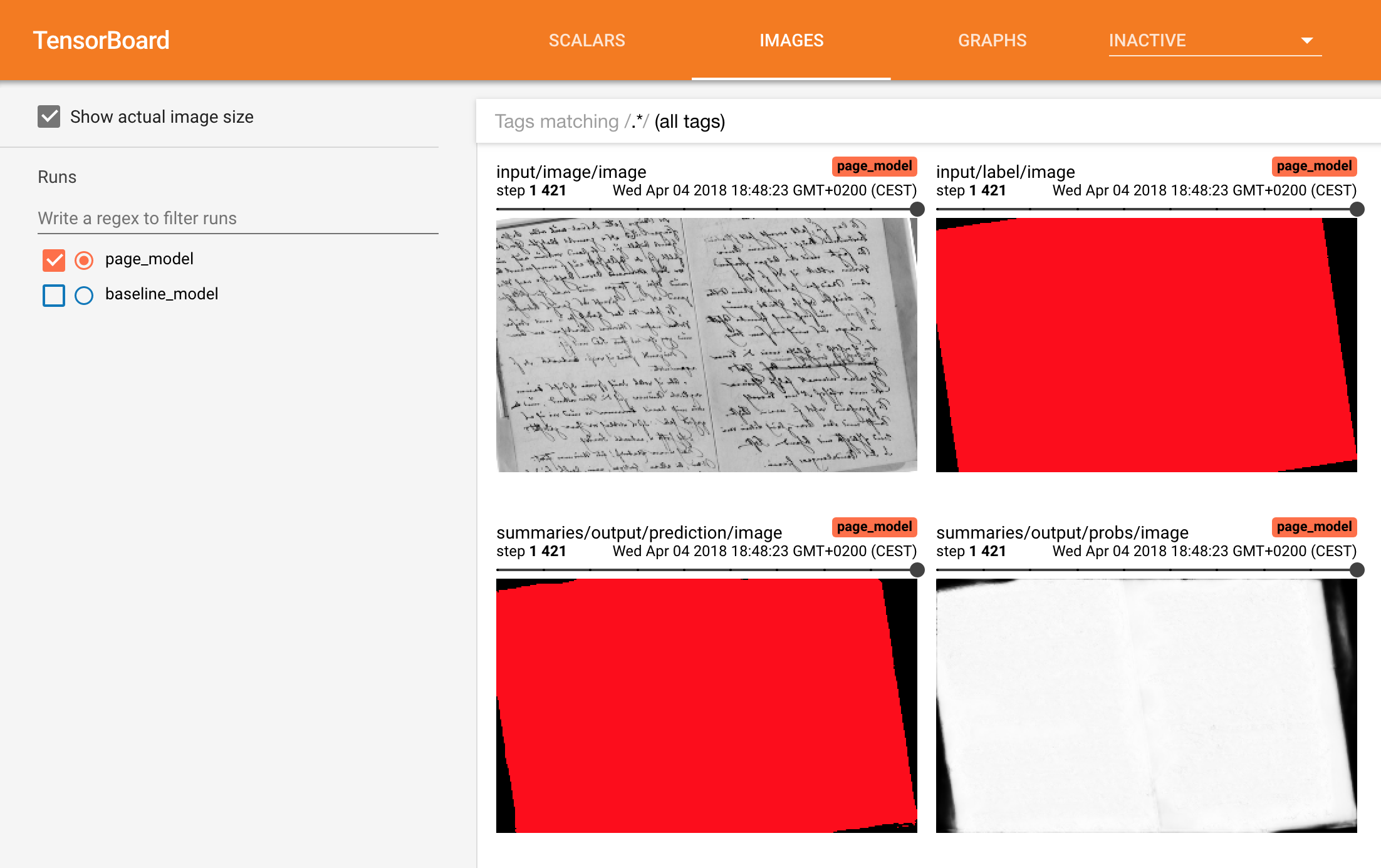
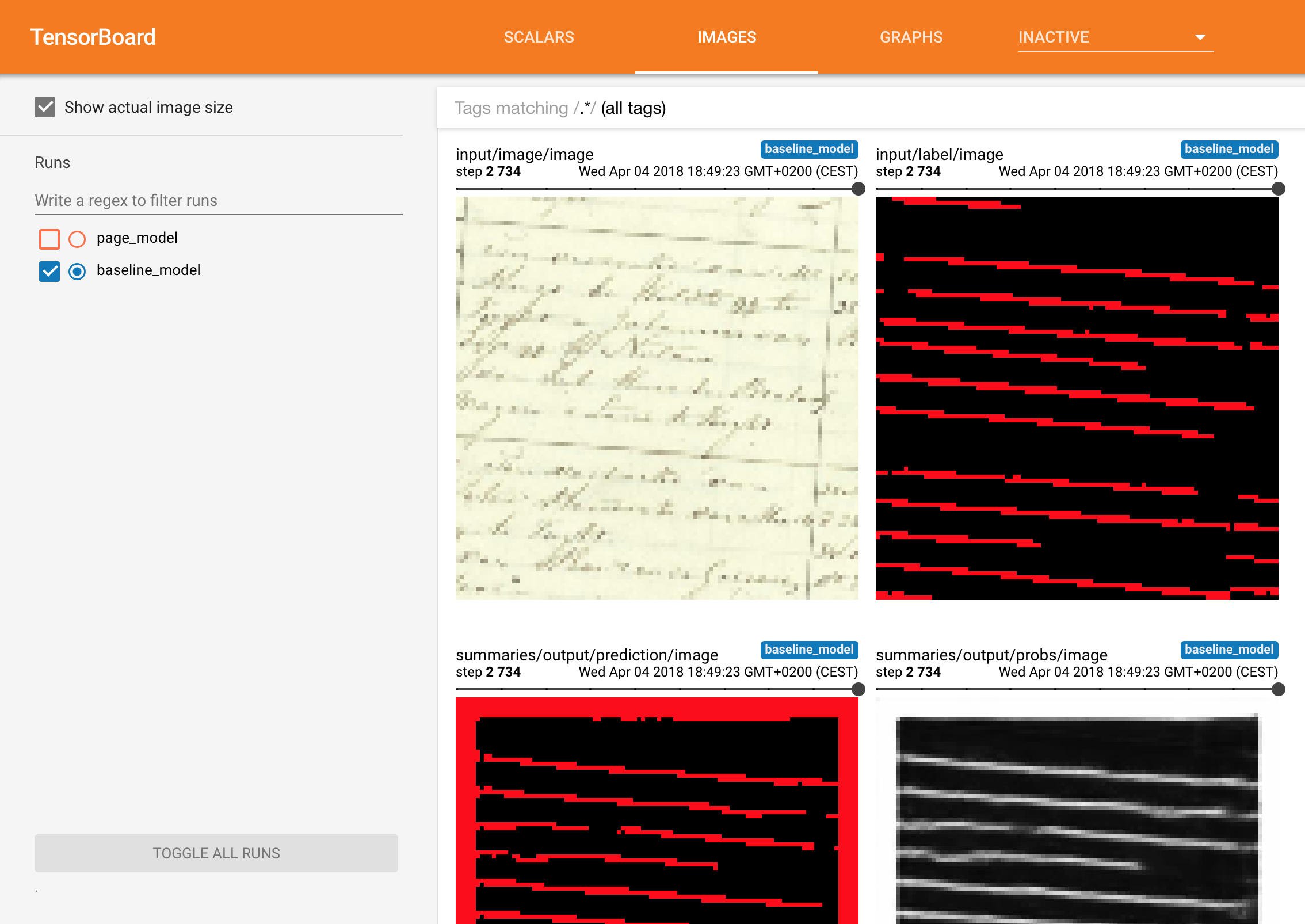
Tensorboard Integration¶
The TensorBoard integration allows to visualize your TensorFlow graph, plot metrics and show the images and predictions during the execution of the graph.